[CODEGATE 2025 Quals] writeups
재활이 시급하다. Off-the-record지만, LLM를 사용하는 것을 항상 배척해 오고 있었지만 다른 사람들 writeup을 보니 LLM 사용이 이제는 거의 필수가 되어 버린 것 같다. Exploit code 작성에 대한 방향성을 인간이 계속 제시하고, 인간의 insight으로 LLM에게 코드 분석과 작성에 대해 쿼리를 계속 던지면 유의미한 결과가 나오는 것이 놀라웠다. 다음주 PlaidCTF, 다다음주 DEFCON Quals에는 다 붙여서 두뇌(아님) 풀가동을 시켜야겠다.
cod3matr1x
적당히 Decompile하고 내부 함수들을 분석하고 이름을 붙였다.
// bad sp value at call has been detected, the output may be wrong!
__int64 __fastcall main(int a1, char **a2, char **a3)
{
__int64 v3; // rcx
__int64 v4; // rax
int v5; // eax
int v7; // [rsp+0h] [rbp-4BD8h]
int i; // [rsp+4h] [rbp-4BD4h]
int j; // [rsp+8h] [rbp-4BD0h]
int k; // [rsp+Ch] [rbp-4BCCh]
int m; // [rsp+10h] [rbp-4BC8h]
int n; // [rsp+14h] [rbp-4BC4h]
int ii; // [rsp+18h] [rbp-4BC0h]
int jj; // [rsp+1Ch] [rbp-4BBCh]
int kk; // [rsp+20h] [rbp-4BB8h]
int mm; // [rsp+24h] [rbp-4BB4h]
int nn; // [rsp+28h] [rbp-4BB0h]
int i1; // [rsp+2Ch] [rbp-4BACh]
_DWORD v19[24][24]; // [rsp+38h] [rbp-4BA0h] BYREF
_DWORD v20[24][24]; // [rsp+938h] [rbp-42A0h] BYREF
_DWORD v21[24][24]; // [rsp+1238h] [rbp-39A0h] BYREF
_DWORD v22[24][24]; // [rsp+1B38h] [rbp-30A0h] BYREF
_DWORD v23[24][24]; // [rsp+2438h] [rbp-27A0h] BYREF
_DWORD v24[24][24]; // [rsp+2D38h] [rbp-1EA0h] BYREF
_DWORD v25[24][24]; // [rsp+3638h] [rbp-15A0h] BYREF
_DWORD v26[26][26]; // [rsp+3F38h] [rbp-CA0h] BYREF
_BYTE v27[32]; // [rsp+49C8h] [rbp-210h] BYREF
char input[480]; // [rsp+49E8h] [rbp-1F0h] BYREF
int v29; // [rsp+4BC8h] [rbp-10h]
char v30; // [rsp+4BCCh] [rbp-Ch]
unsigned __int64 v31; // [rsp+4BD0h] [rbp-8h]
while ( v25[15] != v20[7] )
;
v31 = __readfsqword(0x28u);
setlocale(LC_ALL, &locale);
memset(v26, 0, sizeof(v26));
memset(v19, 0, sizeof(v19));
memset(v20, 0, sizeof(v20));
memset(v21, 0, sizeof(v21));
memset(v22, 0, sizeof(v22));
memset(v23, 0, sizeof(v23));
memset(v24, 0, sizeof(v24));
memset(v25, 0, sizeof(v25));
memset(input, 0, sizeof(input));
v29 = 0;
v30 = 0;
v7 = 0;
for ( i = 0; i <= 11; ++i )
{
if ( (i & 1) != 0 )
{
v19[23 - i][i] = 1;
v3 = 23 - i;
v4 = 24LL * i;
}
else
{
v19[0][25 * i] = 1;
v3 = 23 - i;
v4 = 24 * v3;
}
v19[0][v3 + v4] = 1;
}
__isoc99_scanf("%484[^\n]", input);
for ( j = 2; j <= 23; ++j )
{
for ( k = 2; k <= 23; ++k )
{
v5 = v7++;
v26[j][k] = input[v5];
}
}
for ( m = 1; m <= 24; ++m )
{
for ( n = 1; n <= 24; ++n )
{
if ( !v26[m][n] )
v26[m][n] = aC0d3gat3[(n - 1 + m - 1) % 8];
}
}
sum_3x3((_DWORD (*)[26][26])v26, (_DWORD (*)[24][24])v20);
mat_rot_cw_90deg((_DWORD (*)[24][24])v20);
matmul_GF65535((_DWORD (*)[24][24])v20, (_DWORD (*)[24][24])v19, (_DWORD (*)[24][24])v21);
matmul_GF65535((_DWORD (*)[24][24])v19, (_DWORD (*)[24][24])v21, (_DWORD (*)[24][24])v20);
mat_rot_ccw_90deg((_DWORD (*)[24][24])v20);
matadd_GF65535((_DWORD (*)[24][24])v20, (_DWORD (*)[24][24])dword_3220, (_DWORD (*)[24][24])v22);
matmul_GF65535((_DWORD (*)[24][24])v22, (_DWORD (*)[24][24])dword_4D20, (_DWORD (*)[24][24])v23);
matadd_GF65535_uint((_DWORD (*)[24][24])v23, (_DWORD (*)[24][24])dword_3B20, (_DWORD (*)[24][24])v24);
matadd_GF65535_uint((_DWORD (*)[24][24])v23, (_DWORD (*)[24][24])dword_4420, (_DWORD (*)[24][24])v25);
for ( ii = 0; ii <= 23; ++ii )
{
for ( jj = 0; jj <= 23; ++jj )
{
if ( v24[ii][jj] != dword_5620[ii][jj] )
{
puts("Wrong");
return 0LL;
}
}
}
system("clear");
wprintf("\n");
for ( kk = 0; kk <= 23; ++kk )
{
for ( mm = 0; mm <= 23; ++mm )
wprintf("%", dword_3020[v24[kk][mm] - 1]);
for ( nn = 0; nn <= 23; ++nn )
wprintf("%", dword_3020[v25[kk][nn] - 1]);
wprintf("\n");
}
wprintf("\n");
sub_1ACE(input, v27);
wprintf(U"FLAG: codegate2025{");
for ( i1 = 0; i1 <= 31; ++i1 )
wprintf(U"%02x", (unsigned __int8)v27[i1]);
wprintf(U"}\n");
return 0LL;
}다음과 같은 로직이다.
-
26x26 행렬을 초기화한다.
-
밖에 테두리 빼고 안쪽 24x24를
"C0D3GAT3"으로 빗금 칠하듯이 채운다. -
다시 밖의 테두리 빼고 안쪽 22x22를 입력으로 채운다. 여기까지 진행되면 아래와 같은 상태로 채워진다.
0000000000… 000000000000'C''0''D''3'… 'G''A''T''3'0000'0'INPUT...'3''C'0000… … … 0000'3''C''0''D'… '3''G''A''T'0000'C''0''D''3'… 'G''A''T''3'000000000000… 0000000000 -
해당 행렬에 대해, 3x3 Kernel으로 Sum을 구해 24x24 행렬을 만들어서 다음과 같은 연산을 진행한다.
graph TD v26[["v26: 26x26"]] --> k33["3x3 Sum"] k33 --> cw90["CW 90°"] cw90 --> mul65535_0["@ GF(65535)"] v19[["v19: 24x24"]] --> mul65535_0["@ GF(65535)"] v19_[["v19: 24x24"]] --> mul65535_1["@ GF(65535)"] mul65535_0["@ GF(65535)"] --> mul65535_1["Matmul GF(65535)"] mul65535_1["@ GF(65535)"] --> ccw90["CCW 90°"] ccw90 --> add["\+ GF(65535)"] dw3220[["dword_3220: 24x24"]] --> add["\+ GF(65535)"] add --> mul65535_2["@ GF(65535)"] dw4d20[["dword_4D20: 24x24"]] --> mul65535_2 mul65535_2 --> add_["\+ GF(65535)"] dw3b20[["dword_3B20: 24x24"]] --> add_ add_ <==> dw_5620["dword_5620: 24x24"]
Restoring v20
1차적인 목표는 연산에 사용된 각 Array들을 가져오고, 상에서 행렬 연산을 진행해 최종적으로 3x3 Sum을 수행한 직후의 v20을 복원하는 것이다.
dword_xxxx는 직접 데이터 섹션에서 가져오고, v19 같은 경우는 런타임에 결정이 되기 때문에 적절히 Breakpoint를 잡고 값을 gdb에서 출력할 수 있다.
v19를 생성한 로직이 끝난 직후에 gdb에서 pi를 사용해 다음 python script를 실행했다.
import gdb
import numpy as np
rbp = gdb.newest_frame().read_register('rbp')
x = gdb.selected_inferior().read_memory(rbp - 0x4ba0, 4 * 24 * 24).tobytes()
mem = struct.unpack("@576i", x)
mem = np.array(mem, dtype=np.int32).reshape((24, 24))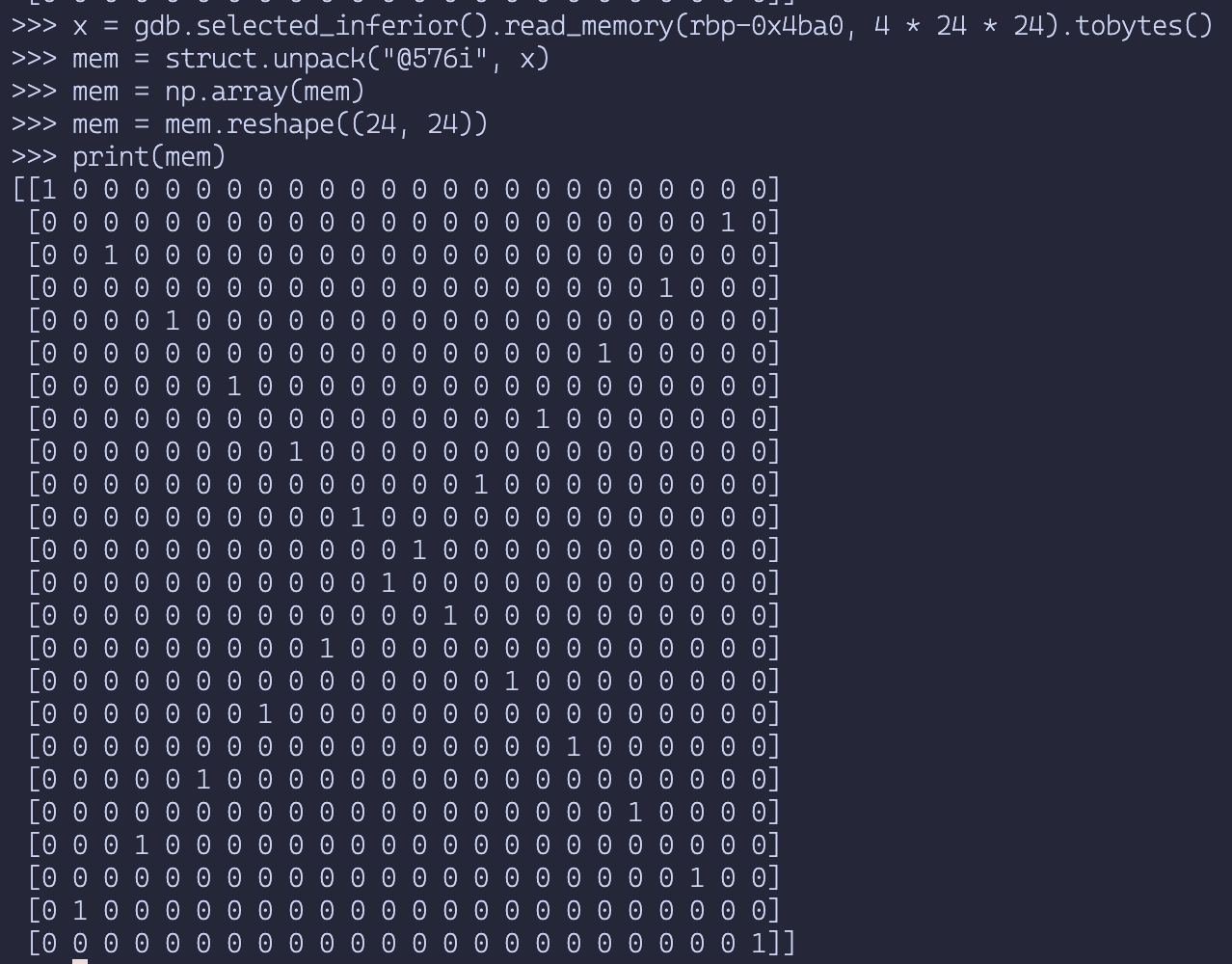
v19의 결과이다.
각 계산의 단계별로 역산하는 파트는 다음과 같다.
elf = ELF("./codematrix")
def fetch_matrix(addr, row, col):
raw_mat = elf.read(addr, 4 * row * col)
raw_mat = struct.unpack(f"@{row*col}i", raw_mat)
n_mat = np.array(raw_mat, dtype=np.int32)
n_mat = n_mat.reshape((row, col))
return n_mat
dw_3220 = Matrix(IntegerModRing(65535), fetch_matrix(0x3220, 24, 24).tolist())
dw_4d20 = Matrix(IntegerModRing(65535), fetch_matrix(0x4D20, 24, 24).tolist())
dw_3b20 = Matrix(IntegerModRing(65535), fetch_matrix(0x3B20, 24, 24).tolist())
dw_5620 = Matrix(IntegerModRing(65535), fetch_matrix(0x5620, 24, 24).tolist())
v19 = [
[1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0],
[0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0],
[0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0],
[0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0],
[0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1],
]
v19 = Matrix(IntegerModRing(65535), v19)
def ccw_90(a):
return Matrix(IntegerModRing(65535), np.rot90(a, k=1).tolist())
def cw_90(a):
return Matrix(IntegerModRing(65535), np.rot90(a, k=-1).tolist())
v23 = dw_5620 - dw_3b20
v22 = v23 * dw_4d20.inverse()
v22 = v22 - dw_3220
v20 = cw_90(v22)
v20 = v19.inverse() * v20 * v19.inverse()
v20 = ccw_90(v20)Restoring v26
v26을 정의하고, z3을 통해 복원한다. 최초 입력은 22x22이고, 거기에 패딩이 두 번 ("C0D3GAT3" 으로 안쪽, b"\x00"으로 바깥쪽) 들어가게 된다.
입력이 v26에 복사되고, 남는 길이는 "C0D3GAT3"로 채워지게 된다.
Res = np.array(v20, dtype=np.int32).reshape((24, 24)).tolist()
Padding = "C0D3GAT3"
S = Solver()
M_26x26 = [[Int(f"m26_{i}_{j}") for j in range(26)] for i in range(26)]
Input = [[Int(f"input_{i}_{j}") for j in range(24)] for i in range(24)]
for i in range(26):
for j in range(26):
if i == 0 or j == 0 or i == 25 or j == 25: # Outer padding: "\x00"
S.add(M_26x26[i][j] == 0)
elif i == 1 or j == 1 or i == 24 or j == 24: # Inner padding: "C0D3GAT3"
S.add(M_26x26[i][j] == ord(Padding[(i + j - 2) % 8]))
else:
S.add(
If(
Input[i - 2][j - 2] == 0, # IF end of input
M_26x26[i][j] == ord(Padding[(i + j - 2) % 8]), # THEN Pad with "C0D3GAT3"
M_26x26[i][j] == Input[i - 2][j - 2], # ELSE copy input
)
)
# 3x3 Sum
for i in range(24):
for j in range(24):
S.add(
(
M_26x26[i][j]
+ M_26x26[i][j + 1]
+ M_26x26[i][j + 2]
+ M_26x26[i + 1][j]
+ M_26x26[i + 1][j + 1]
+ M_26x26[i + 1][j + 2]
+ M_26x26[i + 2][j]
+ M_26x26[i + 2][j + 1]
+ M_26x26[i + 2][j + 2]
)
== Res[i][j]
)
if S.check() == sat:
M = S.model()
Sol = [chr(M.eval(Input[i // 22][i % 22]).as_long()) for i in range(22 * 22)]
print("".join(Sol))
else:
print("Unsat")조건을 적당히 주어서 최초 입력을 복원할 수 있다. 해당 입력을 바이너리에 넣어 Flag를 얻는다.
$ sage -python sol.py
[!] Could not populate PLT: Cannot allocate 1GB memory to run Unicorn Engine
[*] '/Users/aplace/Downloads/Codegate2025/codematrix'
Arch: amd64-64-little
RELRO: Full RELRO
Stack: Canary found
NX: NX enabled
PIE: PIE enabled
SHSTK: Enabled
IBT: Enabled
C0DEGATE 1s a gl0ba1 internationa1 hacking d3f3ns3 competition and 5ecurity conference. Held annually since 2008, C0D3GAT3 is known as the Olympics for hackers, wh3re hack3rs and security 3xperts from around the world gath3r t0 c0mpet3 for the title of the w0rld's best hack3r. In addition to fierce competition among tru3 white-hat hackers, a juni0r division is also he1d, s3rv1ng as a p1atform f0r discover1ng talented 1ndividuals 1n th3 fi3ld of cyb3rsecurity. You are good hacker.지금 푼것도 대회 끝나고 왜안됨 억까를 해결하고 그나마 풀어낸 문제이다. 제 실력이 안나오는 것 같아서 착잡하다. 시험기간 + 매우 중요한 CTF 가 2주 연속이어서 이 모든게 끝나면 병원을 가야겠다.