Tomojiksi
Rust로 짜인 바이너리 리버싱이다. 포카전때 중요하게 쓰였던 아이디어를 처음 구상했던 문제였으며, 해당 아이디어를 사용해 이 문제를 매우 수월하게 풀 수 있었다.
Analyzing flag printing logic
Condition for opening ./flag.txt
@ sub_9930 + 1814 (B144): string reference to ./flag.txt
해당 sub_9930 + 1814 (B144) 위치에 flag.txt에 접근한다. 이에 도달하기 위해서는:
@ sub_9930 + 16B8 (AFE8): jump should taken with
0x55555555efe8: cmp rcx, 0x400 0x55555555efef: je 0x55555555f129
rcx == 0x400으로 세팅을 해야 한다. (On IDA: v52 == 1024)
v52 = 4 while ( *(_OWORD *)&v39[v52 - 4] == __PAIR128__( __PAIR64__(*((_DWORD *)&v76 + v52 + 1), *((_DWORD *)&v76 + v52)), __PAIR64__(*((_DWORD *)&v75 + v52 + 1), *((_DWORD *)&v75 + v52)))) { if ( v52 == 1024 ) { // Flag print routine } v53 = v39[v52] == *((_DWORD *)&v77 + v52); v52 += 5LL; if ( !v53 ) break; }
해당 루틴은 v39와 v77이 같은지를 판별하는 루틴이다.
while loop의 시작인 sub_9930 + 1680 (AFB0)에 Breakpoint를 걸고 메모리를 체크해 본다.
Input format
if ( v16 == '1' ) { LABEL_40: if ( v15 == (_QWORD)v61 ) { sub_B690(&p_ptr, v15); v15 = *((_QWORD *)&v61 + 1); } *((_DWORD *)p_ptr + v15) = 1; goto LABEL_27; } } LABEL_30: if ( v16 != '0' ) { *(_QWORD *)fd = v71; *(_QWORD *)&v67 = sub_411E0; ptr = &off_54FA0; *(_QWORD *)&v63 = 1LL; *((_QWORD *)&v63 + 1) = fd; v64 = 1uLL; sub_83D0((__int64)&ptr, (__int64)&off_54FB0); } if ( v15 == (_QWORD)v61 ) { sub_B690(&p_ptr, v15); v15 = *((_QWORD *)&v61 + 1); } *((_DWORD *)p_ptr + v15) = 0; LABEL_27: v15 = ++*((_QWORD *)&v61 + 1);
입력으로 '0' or '1'만을 받는 것을 확인할 수 있었다. 따라서 입력 형식은 길이 1024의 Binary string이다.
Fetching array to compare
분석 과정에서 xmm 레지스터를 통해 movaps 로 xmmword_440F0 부터 메모리를 옮긴다. 해당 루틴의 위치인 sub_9930 + FF9 (A929)에 Breakpoint를 걸고, 스택에 옮긴 위치인 0x7FFFFFFFC8A0 으로부터 4096 bytes를 가져 온다 (sizeof(__DWORD) * 1024). 다음 gdbscript를 통해 옮길 수 있다.
import gdb
import struct
BASE = 0x555555554000
CMPTBL_SET_ADDR = BASE + 0xA929
CMPTBL_OFFSET = 0x7FFFFFFFC8A0
SIZEOF_DWORD = 4
FLAG_LEN = 1024
gdb.execute("file ./Tomojiski")
cmptbl_set_bp = gdb.Breakpoint(f"*{CMPTBL_SET_ADDR}")
cmptbl_set_bp.silent = True
gdb.execute(f"run program <<< {'0' * FLAG_LEN} > /dev/null")
cmp_table = list(struct.unpack(f'<{FLAG_LEN}L', gdb.selected_inferior().read_memory(CMPTBL_OFFSET, SIZEOF_DWORD * FLAG_LEN).tobytes()))
with open("cmptable.txt", "w") as f:
f.write('\n'.join(cmp_table))
출력은 다음과 같다.
cmptable.txt
3 4 5 6 6 6 12 13 ... 1024 3 2 1024(Total 1024 lines)
Fetching array to be compared
while loop에 Breakpoint를 세팅하고 포맷에 맞는 임의의 입력을 주었다. ('0' * FLAG_LEN) 이후 프로그램을 실행하고, breakpoint에 닿았을 때 연산되어 heap에 저장된 값들을 살펴보았다. 다음의 gdbscript를 사용했다.
import gdb
BASE = 0x555555554000
CHECK_ADDR = BASE + 0xAFB0
MEM_OFFSET = 0x5555559C4550
SIZEOF_DWORD = 4
FLAG_LEN = 1024
gdb.execute("file ./Tomojiski")
check_bp = gdb.Breakpoint(f"*{CHECK_ADDR}")
check_bp.silent = True
gdb.execute(f"run program <<< {'0' * FLAG_LEN} > /dev/null")
print(struct.unpack(f'<{FLAG_LEN}L', gdb.selected_inferior().read_memory(MEM_OFFSET, SIZEOF_DWORD * FLAG_LEN).tobytes()))
(0, 0, 0, 0, 0, 0, 0, ... , 0, 0, 0, 0, 0, 0, 0)
1024개의 0으로 차있는 것을 확인하였다.
Understanding internal logic for setting heap memory (Part 1)
여기서 해당 로직을 이해하기 위해 Basis vector를 입력하여 어떤 연산이 진행되는지 관찰하고자 했다. 이후, Basis vector를 조합하는 개수를 늘려 나가면서 패턴을 발견하고자 했다.
- 1024차원의 Basis vector (
("0" * t) + "1" + ("0" * (1023 - t))형태)를 입력한다. - Basis vector 2개를 더해서 입력한다.
- Basis vector 3개를 더해서 입력한다.
- (패턴 찾을 때 까지 노가다)
Input standard basis
gdb.execute("file ./Tomojiski")
check_bp = gdb.Breakpoint(f"*{CHECK_ADDR}")
check_bp.silent = True
for i in range(10):
vector = ['1' if t == i else '0' for t in range(FLAG_LEN)] # basis vector
gdb.execute(f"run program <<< {''.join(vector)} > /dev/null", to_string=True)
print(struct.unpack(f'<{FLAG_LEN}L', gdb.selected_inferior().read_memory(MEM_OFFSET, SIZEOF_DWORD * FLAG_LEN).tobytes()))
gdb.execute("kill")
i = 0 (100000...0000) -> (1, 1, 1, 1, 1, 1 ... , 1, 1, 1, 1, 1) i = 1 (010000...0000) -> (0, 2, 1, 1, 1, 1 ... , 1, 1, 1, 1, 1) i = 2 (001000...0000) -> (0, 0, 3, 1, 1, 1 ... , 1, 1, 1, 1, 1) i = 3 (000100...0000) -> (0, 0, 0, 4, 1, 1 ... , 1, 1, 1, 1, 1) i = 4 (000010...0000) -> (0, 0, 0, 0, 5, 1 ... , 1, 1, 1, 1, 1)
다음과 같은 패턴이 나타나는 것을 확인했다.
V[t][i] = 0 ... (t < i)
V[t][i] = t + 1 ... (t == i)
V[t][i] = 1 ... (t > i)Input vector combinations with 2 standard basis
gdb.execute("file ./Tomojiski")
check_bp = gdb.Breakpoint(f"*{CHECK_ADDR}")
check_bp.silent = True
for i in range(1, 10):
vector = ['1' if t in [0, i] else '0' for t in range(FLAG_LEN)]
gdb.execute(f"run program <<< {''.join(vector)} > /dev/null", to_string=True)
print(struct.unpack(f'<{FLAG_LEN}L', gdb.selected_inferior().read_memory(MEM_OFFSET, SIZEOF_DWORD * FLAG_LEN).tobytes()))
gdb.execute("kill")
i = 1 (110000...0000) -> (2, 3, 2, 2, 2, 2 ... , 2, 2, 2, 2, 2) i = 2 (101000...0000) -> (1, 2, 4, 2, 2, 2 ... , 2, 2, 2, 2, 2) i = 3 (100100...0000) -> (1, 1, 2, 5, 2, 2 ... , 2, 2, 2, 2, 2) i = 4 (100010...0000) -> (1, 1, 1, 2, 6, 2 ... , 2, 2, 2, 2, 2) i = 5 (100001...0000) -> (1, 1, 1, 1, 2, 7 ... , 2, 2, 2, 2, 2)
해당 출력들도 다음과 같이 2개의 Basis vector들의 결과로 합성된 것을 확인했다.
i = 1 (110000...0000) -> (2, 3, 2, 2, 2, 2 ... , 2, 2, 2, 2, 1) = (1, 1, 1, 1, 1, 1 ... , 1, 1, 1, 1, 1) + (1, 2, 1, 1, 1, 1 ... , 1, 1, 1, 1, 0) i = 2 (101000...0000) -> (1, 2, 4, 2, 2, 2 ... , 2, 2, 2, 2, 1) = (1, 1, 1, 1, 1, 1 ... , 1, 1, 1, 1, 1) + (0, 1, 3, 1, 1, 1 ... , 1, 1, 1, 1, 0) i = 3 (100100...0000) -> (1, 1, 2, 5, 2, 2 ... , 2, 2, 2, 2, 1) = (1, 1, 1, 1, 1, 1 ... , 1, 1, 1, 1, 1) + (0, 0, 1, 4, 1, 1 ... , 1, 1, 1, 1, 0) and on...
Input vector combinations with 3 standard basis
위와 같은 방식으로 해당 프로그램의 연산 로직이 선형 독립임을 알아냈다.
Part 1 Conclusion
- Basis vectors:
$$ \vec{V}(i_k) \cdot \hat{\bf{e}}_k = 1 \space (0 \le k \le 1023) \\ \vec{V}(i_k) \cdot \hat{\bf{e}}_i = 0 \space\cdots (i \ne k, 0 \le i, k \le 1023) $$
- Combination of $N$ vectors is:
$$ \vec{V}(i_0, i_1, i_2 ... i_n) = \sum_{k=0}^{n} GenerateVector(i_k, k) \space\cdots (i_k > k) $$
- 결과 vector는 입력에 해당하는 vector의 combination으로 이루어져 있다.
- 결과 vector를 분해하기 위해 필요한 파라미터는 다음과 같이 2개가 있다.
- # of standard basis. (Corresponding index on the input string is 1)
- Entry # of combination.
(# of standard basis) < (Entry # of combination) 를 만족한다.
Understanding internal logic for setting heap memory (Part 2)
Vector를 성분으로 분해하는 함수로 다음과 같이 gdbscript를 작성했다.
def vector_subtract(vctA: list[int], vctB: list[int]) -> list[int]:
assert len(vctA) == FLAG_LEN and len(vctB) == FLAG_LEN
return [a - b for a, b in zip(vctA, vctB)]
def fetch_vector(x: int, y: int) -> list[int]:
before_string = ['1'] * y + ['0'] * (1024 - y)
after_string = ['1'] * y + ['0'] * (1024 - y)
after_string[x] = '1'
gdb.execute(f"run program <<< {''.join(before_string)} > /dev/null", to_string=True)
fet_table_first = list(struct.unpack(f'<{FLAG_LEN}L', gdb.selected_inferior().read_memory(MEM_OFFSET, SIZEOF_DWORD * FLAG_LEN).tobytes()))
gdb.execute("kill")
gdb.execute(f"run program <<< {''.join(after_string)} > /dev/null", to_string=True)
fet_table_second = list(struct.unpack(f'<{FLAG_LEN}L', gdb.selected_inferior().read_memory(MEM_OFFSET, SIZEOF_DWORD * FLAG_LEN).tobytes()))
gdb.execute("kill")
return vector_subtract(fet_table_second, fet_table_first)
GenerateVector function의 동작은 다음과 같다. gdb에서 확인했을 때 basis + n_entry < FLAG_LEN 부분만을 확인했으나, 몇 시간의 더욱 많은 노가다를 통해 이외의 부분을 발견해낼 수 있었다.
def generate_vector(basis: int, entry_no: int) -> list[int]:
if basis + n_entry < FLAG_LEN:
V = [0] * basis + [basis + 1] + ([1] * (1023 - basis))
for i in range(n_entry):
V[basis - i - 1], V[-(i + 1)] = V[-(i + 1)], V[basis - i - 1]
return V
else:
V = [0] * (basis - n_entry) + [1] * (FLAG_LEN - basis) + [0] * n_entry
V[basis] = basis
return VPart 2 Conclusion
GenerateVector(j, k) 함수 (j > k)는 다음과 같은 vector를 반환한다
If j + k < 1024:
0 <---------------------- j --------------------> 1023 (0 0 0 0 ... 0 0 0 1 1 1 (j+1) 1 1 1 1 1 ... 1 0 0 0) ----- ----- k kIf j + k >= 1024:
0 <--------------------- j -----------------> 1023 (0 0 0 1 ... 1 1 1 0 0 0 j 0 0 0 0 0 ... 0 0 0) ----- |<------------ k----------->| j-k
Restoring input
cmp_table에서 얻어낸 1024 길이의 vector를 GenerateVector 함수의 결과로 분해해야 한다. 여기서, GenerateVector 함수의 두 번째 인자인 k의 증가함에 따라 첫 번째로 1이 나타나는 위치가 뒤로 밀린다. 따라서 Greedy하게 k를 0부터 시작하여 vector를 생성, 해당 벡터만이 span할 수 있는 cmp_table의 벡터 원소를 0으로 만들도록 하는 벡터를 빼고 k를 증가시키는 과정을 반복한다.
이 과정을 1024회 반복 이후 cmp_table은 0으로 차있어야 한다.
restored = ['0' for _ in range(0x400)]
while basis < 0x400:
while not is_vector_subtractable(cmp_table, generate_vector(basis, n_entry)):
basis += 1
cmp_table = vector_subtract(cmp_table, generate_vector(basis, n_entry))
restored[basis] = '1'
basis += 1
n_entry += 1Final solver & Flag
import gdb
import struct
from functools import reduce
import operator
FLAG_LEN = 0x400
"""
First phase - fetching `cmp_table`
"""
BASE = 0x555555554000
CMPTBL_SET_ADDR = BASE + 0xA929
CMPTBL_OFFSET = 0x7FFFFFFFC8A0
SIZEOF_DWORD = 4
gdb.execute("file ./Tomojiski")
cmptbl_set_bp = gdb.Breakpoint(f"*{CMPTBL_SET_ADDR}")
cmptbl_set_bp.silent = True
gdb.execute(f"run program <<< {'0' * FLAG_LEN} > /dev/null")
cmp_table = list(struct.unpack(f'<{FLAG_LEN}L', gdb.selected_inferior().read_memory(CMPTBL_OFFSET, SIZEOF_DWORD * FLAG_LEN).tobytes()))
gdb.execute("kill")
"""
Vector operations
"""
def generate_vector(basis: int, n_entry: int) -> list[int]:
if basis + n_entry < FLAG_LEN:
V = [0] * basis + [basis + 1] + ([1] * (1023 - basis))
for i in range(n_entry):
V[basis - i - 1], V[-(i + 1)] = V[-(i + 1)], V[basis - i - 1]
return V
else:
V = [0] * (basis - n_entry) + [1] * (FLAG_LEN - basis) + [0] * n_entry
V[basis] = basis
return V
def vector_add(vctA: list[int], vctB: list[int]) -> list[int]:
assert len(vctA) == FLAG_LEN and len(vctB) == FLAG_LEN
return [a + b for a, b in zip(vctA, vctB)]
def vector_subtract(vctA: list[int], vctB: list[int]) -> list[int]:
assert len(vctA) == FLAG_LEN and len(vctB) == FLAG_LEN
return [a - b for a, b in zip(vctA, vctB)]
def is_vector_subtractable(vctA: list[int], vctB: list[int]) -> list[int]:
assert len(vctA) == FLAG_LEN and len(vctB) == FLAG_LEN
return reduce(operator.and_, [a >= b for a, b in zip(vctA, vctB)])
"""
Final phase - vector decomposition
"""
basis = 0
n_entry = 0
restored = ['0' for _ in range(0x400)]
while basis < 0x400:
while not is_vector_subtractable(cmp_table, generate_vector(basis, n_entry)):
basis += 1
cmp_table = vector_subtract(cmp_table, generate_vector(basis, n_entry))
restored[basis] = '1'
basis += 1
n_entry += 1
assert reduce(operator.or_, cmp_table) == False # Ensure all elements are zero
print(''.join(restored))
cmp_table을 성공적으로 분해할 수 있었으며, 분해된 출력은 다음과 같다. Remote에 입력해 플래그를 딸 수 있었다.
1110001110000011100000111110111100011001001101001011111000100100000011111110111011111000010110001101000000000101000101000000011011111011101101001111010001101101111011100011100100100011001111110100101000000100010100111000010011011100010100001011111010111001011011001000110111011010001011011000011010011111111101001010100100010010110111111101010111010110101110001000010100100100001111010010101001100100000110111011111110111010111010101010000101101001101010000010100000111011100111101001011110010011100000000011000001100101110010010001000110001000001010111111100110011101010100000111010001010010110100010100001011111111100110111111110101101100110010001000001100101011011011110000111100110000010000101001000010100011000100010111101110101011011101100011010000010010000111101010000111101111111100011111011001110011100111111101111011101000101110101100011111101010100110000011111010111101110000101101111110011011001001001010000100010000001011001010011001011001011111101101011110001011111010000110101100011000111000010110111101011001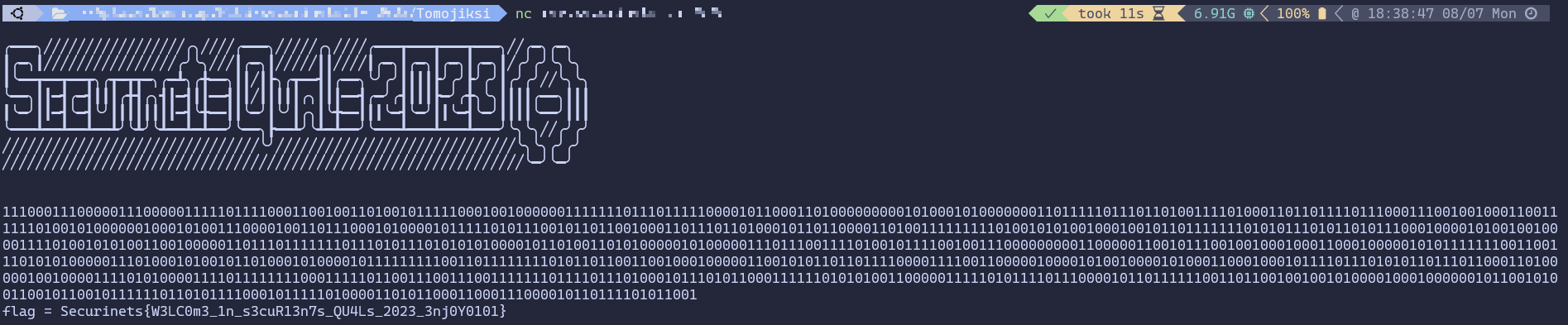
FLAG = Securinets{W3LC0m3_1n_s3cuR13n7s_QU4Ls_2023_3nj0Y0101}
'Writeups' 카테고리의 다른 글
| [bi0sctf 2024] writeups (0) | 2024.03.04 |
|---|---|
| [dicectf 2024] writeups (0) | 2024.02.06 |
| [insomnihack 2024] writeups (0) | 2024.01.26 |
| [dreamhack.io] multipoint2 (0) | 2024.01.11 |


